03. 캐시 기억 장치
※ 기본 개념
- 캐시의 사용 목적과 특징 : CPU와 주기억장치 사이에 존재하며 속도 차이를 줄여주어 CPU에서의 데이터와 명령어 처리 속도를 향상시키는 고속 반도체 기억장치이다. 주기억장치보다 액세스 속도가 높은 칩을 사용하지만 가격과 제한된 공간 때문에 용량이 적다.
- 캐시 기억장치를 포함하고 있는 컴퓨터 시스템에서 캐시의 동작
- miss인 경우 : CPU가 명령어를 인출하기 위해 캐시 기억장치에 접근했는데 명령어가 존재하지 않아 찾지 못했을 때
▶ 1단계 : 주기억장치에서 필요한 정보를 획득하여 캐시 기억장치에 전송
▶ 2단계 : 캐시 기억장치는 얻어진 정보를 다시 중앙처리장치로 전송
- hit인 경우 : CPU가 명령어를 인출하기 위해 캐시 기억장치에 접근하여 그 명령어를 찾았을 때
▶ 캐시 기억장치의 동작은 기억장치 참조의 지역성에 의해 가능
- 캐시의 기본 동작 흐름도

- ★캐시의 히트율과 평균 액세스 시간
▶ 히트율(H) = 캐시에 히트되는 횟수 / 전체 기억장치 액세스 횟수
▶ 미스율(1-H)
▷ 평균 기억장치 액세스 시간(Ta) = H * Tc + (1-H) * (Tc + Tm) ~~ H * Tc + (1-H) * Tm
(c는 캐시 엑세스 시간, Tm은 주기억장치 액세스 시간)
--> 캐시의 히트률이 높아질수록 평균 기억장치 액세스 시간은 캐시 액세스 시간에 접근
- 캐시 설계에 있어서 공통적 목표
▶ 캐시의 히트율 극대화
▶ 캐시 히트인 경우 캐시에서 정보를 읽어 오는 시간 최소화하기
▶ 캐시 미스인 경우 주기억 장치에서 캐시로 정보를 가져오는 데 걸리는 시간 최소화하기
▶ 캐시의 내용이 변경되었을 경우 주기억 장치에 해당 내용을 갱신하는 데 소요되는 시간 최소화
- 캐시 설계 요소(지금부터 구체적으로 알아볼 것)
▶ 캐시 용량, 사상방식, 교체 알고리즘, 쓰기 정책, 라인 크기, 캐시 수
1) 캐시 용량
- 장점 : 용량이 커질수록 히트율이 높아짐
- 단점 : 용량이 커지면 비용이 증가학 정보 인출을 위한 주변 회로가 복잡해져 액세스 시간 길어짐, cpu칩 혹은 메인 보드의 공간에도 제한을 받음
2) 사상 방식
▶ 기본개념
- 블록 : 주기억 장치와 캐시 사이에 이동되는 정보 단위
- 주기억 장치 용량 : 2의 n제곱 워드, 블록 k개 워드 ==> 블록의 수 : 2의 n제곱 / k
- 라인 : m개, 각 라인에 워드 k개 필요 --> 라인 크기 = 주기억장치 블록의 크기
▶ 예)
주기억 장치 용량 128바이트(2의 7제곱)
주기억 장치 주소 = 7비트
워드 길이 = 1바이트
블록 크기 = 4바이트(4개의 워드) --> 주기억장치에는 32개의 블록 존재
캐시크기 = 32바이트
캐시 라인 크기 = 4바이트(블록 크기와 동일)
전체 캐시 라인의 수 = 32/4 = 8개
- 직접 사상 : 주기억 장치의 블록들이 지정된 하나의 캐시 라인으로만 매핑, 내가 갈 수 있는 자리가 정해짐

<직접 사상에서 주소 필드의 구성>
- 한 블록 내에 워드 4개가 들어가서 각 워드를 구별하기 위해 w=2비트 필요.
- 캐시 라인 수가 2의 3제곱이라서 s=3비트
- 태그 필드는 나머지 t=2비트
▶ 주기억장치 블록에 적재될 수 있는 캐시 라인 번호
i = j mod m (i: 캐시라인 번호, j:주기억장치 블록, m:캐시라인 수)
▶ 직접 사상에서 캐시 내부 구성 및 읽기 동작

1. 라인필드가 101이므로 5번 캐시라인 선택
2. 5번 캐시 라인에 태그 비트와 주기억장치주소 태그 필드 비교 -> 모두 11이므로 '히트'
3. 주소 워드 필드가 01이므로 poet중에서 o가 인출되어 cpu로 전송
- 완전 연관 사상 : 직접 사상 방식을 보완한 방식으로, 주기억 장치 블록이 캐시의 어떤 라인으로든 적재가 가능하다. 즉, 자리 지정이 되어있지 않다.

<완전-연관 사상에서 주소 필드의 구성>
- 태그필드 = 주기억장치 블록 번호
- 캐시 라인 번호와 태그 필드는 관련 없음
▶ 완전 연관 사상에서 캐시 내부 구성 및 읽기 동작
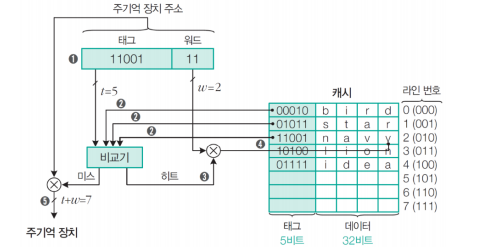
1. 캐시의 모든 라인 태그들과 주기억장치 주소의 태그 필드 내용 비교
2. 2번 캐시라인과 주소 태그 필드 11001이 일치하므로 캐시'히트'
3. 주소 워드 필드가 11이므로 navy중 y가 인출되어 cpu로 전송
**캐시 미스인 경우?
주소 전체가 주기억장치로 보내져 해당 블록을 인출하고 인출된 블록 5번 캐시라인에 저장
▶ 특징
- 주기억 장치의 블록들이 캐시의 어떤 라인으로도 적재 가능
--> 장점 : 데이터의 참조 지역성이 높다면 히트율 매우 높음
단점 : 모든 태그 순차적 비교로 많은 시간 소요
- 실제로 연관 기억장치는 거의 사용되지 않음
- 세트 연관 사상 : 직접 사상과 연관 사상의 조합, 주기억장치 블록 그룹이 하나의 캐시 세트 공유하고 그 세트에는 두 개 이상의 라인들 적재 가능
▶ 전체 캐시 라인(m)은 v개의 세트로 나눔, 각 세트는 k개의 라인으로 구성

- m = 8이었으니까 세트당 캐시 라인의 수가 k=2라면 세트 수는 v=8/2=4개
- 캐시 세트 4개로 구성, 각 세트에 캐시 라인 2개
▶ 세트 연관 사상에서 캐시 내부 구성 및 읽기 동작

1. 세트 번호가 00이므로 캐시의 0번 세트 선택
2. 0번 세트 라인의 태그에 주기억장치 주소의 태그비트 001과 일치하는 것이 있는지 검사
3. 0번 세트 내 첫번째 라인의 태그비트가 001이므로 '히트'
4. 주소 워드 필드가 10이므로 gift중에서 f가 인출되어 cpu로 전송
**미스인 경우?
주소 전체가 주기억장치로 보내져서 해당 블록을 인출하고, 적절한 교체 알고리즘에 의해 2개 중 하나를 선택하여 그 라인에 새로운 블록 적재
3) 교체 알고리즘 : 자리가 지정되어 있지 않은 완전-연관 사상이나 세트-연관 사상에서 적당한 교체 알고리즘이 필요
- LRU : 사용되지 않은 채로 가장 오래 있었던 블록을 교체하는 방식 --> 가장 효과적인 알고리즘
- FIFO : 캐시에 적재된 지 가장 오래된 블록을 교체하는 방식 --> 구현용이 알고리즘이라고 부름
- LFU : 참조되었던 횟수가 가장 적은 블록을 교체하는 방식
- Random : 사용 횟수를 고려하지 않고 후보 캐시 라인 중 임의로 선택하여 교체하는 방식
4) 쓰기 정책 : 캐시에 적재되어 있는 데이터가 수정되었을 때 그 내용을 주기억 장치에 갱신하는 시기와 방법을 결정하는 것
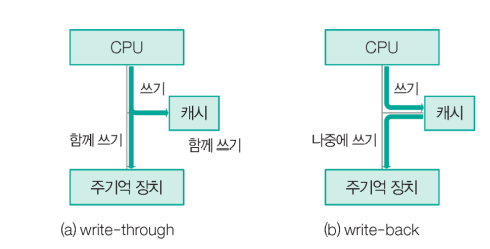
(a) 모든 쓰기 동작들이 캐시로 뿐만 아니라 주기억 장치로도 동시에 수행되는 방식
--> 장점 : 캐시에 적재된 블록의 내용과 주기억장치에있는 그 블록의 내용이 '항상 같음'
단점 : 모든 쓰기 동작이 주기억장치 쓰기를 포함하므로 쓰기 시간이 길어짐
(b) 캐시에서 데이터가 변경되어도 주기억장치에는 갱신되지 않는 방식
--> 장점 : 기억장치에 대한 쓰기 동작의 횟수가 최소화되고, 쓰기 시간이 '짧아짐'
단점 : 캐시의 내용과 주기억장치의 해당 내용이 서로 다름
'공부 > 컴퓨터구조' 카테고리의 다른 글
| [12주차]기억장치(3), 보조기억장치(1) (0) | 2021.05.19 |
|---|---|
| [10주차]제어장치(2), 기억장치 (0) | 2021.05.06 |
| [9주차]제어장치(2) (0) | 2021.05.01 |
| [6주차]레지스터, 컴퓨터 명령어, 주소 지정 방식, 컴퓨터 시스템의 동작 (0) | 2021.04.09 |
| [4주차]디지털 논리 회로-조합 논리 회로,집적 회로 /중앙 처리 장치~ (0) | 2021.04.03 |



